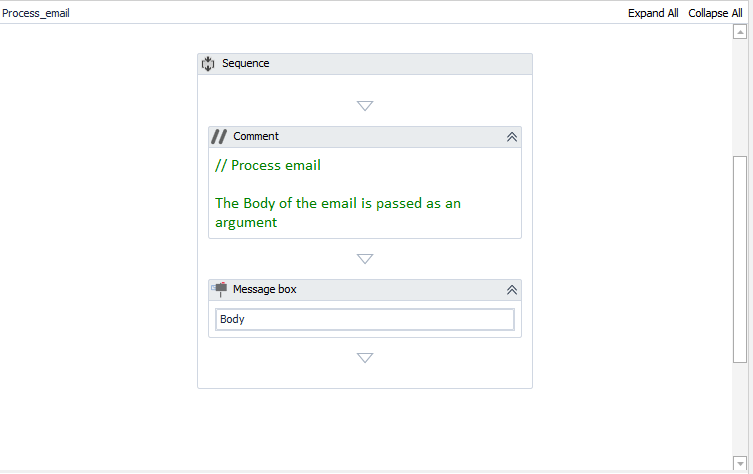
PDF will contain Native text or scanned copy data.
1. Text
and images will contain PDF documents
2. Large
texts or specific texts
3. Read
PDF text activity to read PDF text data but it won’t read image based data
4. Read
PDF will contain Range parameter, which will used for complete doc (ALL pages) or
specific pages or one particular page.
OCR Based PDF activity
1. Google
or Microsoft or Abbyy
2. Different
engines have different parameters
3. OCR
quality is not good and it will more imply with original document
4. Which
is not preferable most of the time because of information will not segregated
as per original PDF document
5. Whenever
possible to use non OCR methods
6. OCR
will read image along with text of the PDF documents
Screen scraping
1. In screen scraping document will display as
per original like spaces and lines as well
Specific element extraction In PDF document
1. Get
text activity will extract specific element
2. Get
text element will use selector to extract specific element for the similar PDF documents
3. In
selector Attach to live element will easy to fix for specific element
4. In
selector open ui explorer we can use to modify as per our requirements and it
give new selector information.
Another Based activity
1. Anchor
based activity
a. In
Anchor based activity we will use find element activity to modify the selector
for wildcard so that it can be useful when same doc contain different values
b. Which
contain Anchor position which will more useful, where the value is present and
will pick it from easily
c. It
will work for same structure PDF file
d. Which
is more flexible compare with earlier ones
e. It’s
more reliable
f.
For screen scraping and Anchor based element PDF document
should be in open status otherwise Uipath will through an error


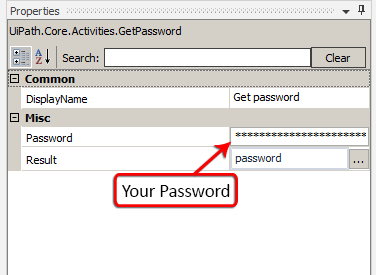
 This is how it's done with UiPath:
This is how it's done with UiPath: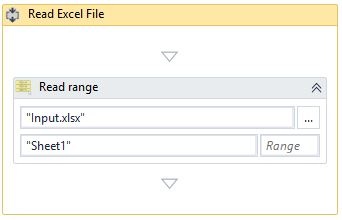
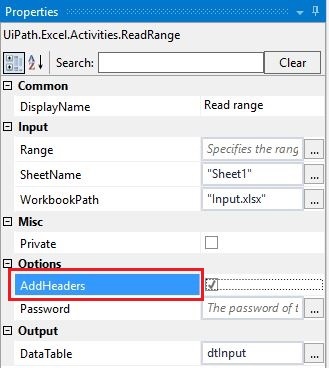
 Step 3: Lookup Using For Each
Step 3: Lookup Using For Each This is quite self explanatory. The key here is to set the correct condition:
This is quite self explanatory. The key here is to set the correct condition:  Key points:
Key points: